A tale of responsible disclosure
Since I originally discovered this bug as part of a bounty program, the time to resolution was very quick for that particular company. However, using Shodan I quickly found around 200 other vulnerable servers. Below I will walk you through the efforts that followed in trying to identify and resolve the issue for as many affected parties as possible.
Rather than being content with having a security fix pushed out and trusting that affected parties will have their systems patched in no time (right?), I decided to go all out and see if I could speed up the patch process and minimize future exploitation of the bug by identifying as many vulnerable parties as I could, and trying to get in contact with all of them to disclose the vulnerability to them.
My methodology, if you can call it that, consisted mostly of frantically searching Google, Shodan, RiskIQ and Passive DNS records to identify asset owners and their contact details. This has been only partially successful, as the numbers at the end of this article will show you.
For the record and for future reference, I have tried to formalize my way of working below.
For the vulnerable source code:
- Identify the author of the source code;
- Make first contact to confirm ownership;
- If available, follow community guidelines (e.g. Rubygems have a pretty good outline of how to proceed);
- Make a suggestion as to how the vulnerability can be mitigated;
- If necessary, fork the open source project and apply security fix yourself;
Note that by applying security fixes in an open source project, you are de facto publishing sensitive details about the vulnerability. I found it difficult to find a good balance in resolving the root cause of the issue and responsibly informing affected parties, without alerting all the evil hackers out there looking for easy exploits to grow their botnets.
For every vulnerable asset:
- Identify the asset owner (company / individual)
- Figure out contact details (mail address, Twitter, Facebook, Telegram, web form, …)
- Make first contact to:
- request what internal procedures are;
- in case of doubt, ensure the identified assets do indeed belong to them;
- Disclose sufficient information to resolve the issue without sharing sensitive vulnerability details or PoC; or
- Request PGP keys to be able to share information containing sensitive vulnerability details and/or PoC;
- Share the information as well as mitigation steps, and a responsible disclosure horizon, after which the information will be made public;
- Request confirmation of a fix;
Below are some screenshots of what these workflows looked like in practice:
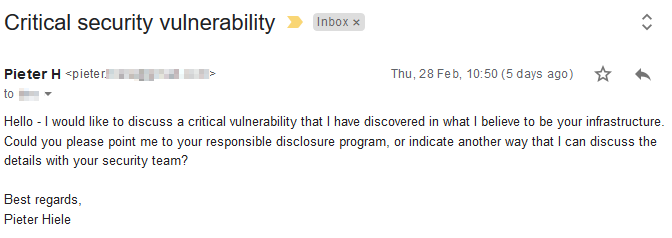
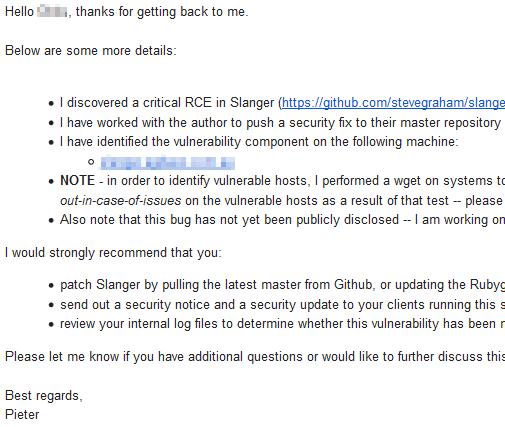
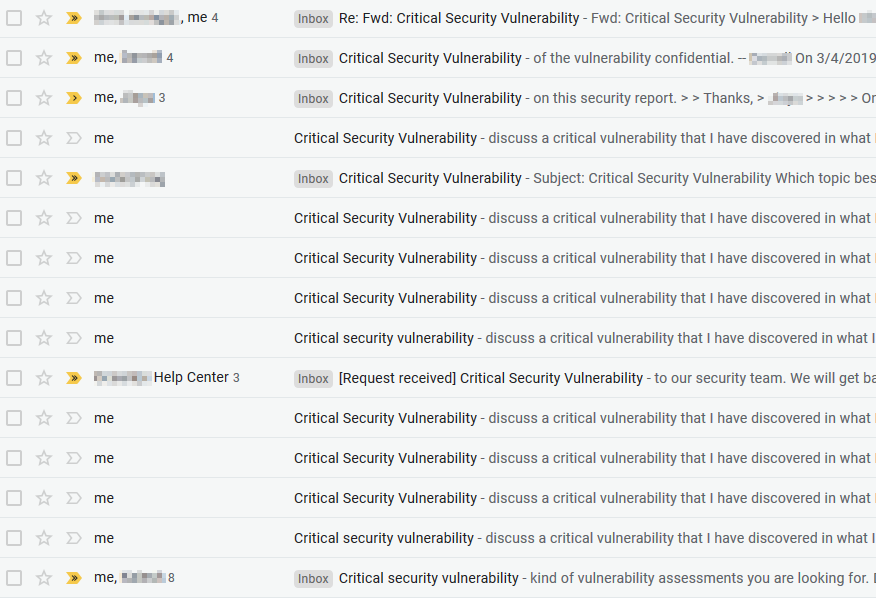
In the process of contacting the owners of vulnerable servers — or trying to — I faced a number of recurring challenges that I find worth listing:
- No contact details on website;
- No identifiable information on a server (e.g. plain Apache install);
- Communication only possible through a web form without clear confirmation that a message was sent;
- Language barriers, e.g. multiple websites were in Chinese, Korean or Spanish only, making my attempts considerably harder;
- Very slow (to none at all) response times in email communication;
- Weeks of delay in trying to get secure PGP communication working;

Finally, I want to share a couple of figures to illustrate the scope of the issue, as well as the difficulties that arise from trying to responsibly disclose a critical open source bug:
- 200+ vulnerable hosts identified;
- 30+ different asset owners identified;
- ~57% of asset owners contacted;
- ~26% have responded to my message and received details about specifics and how to mitigate — the other 30% have never responded to my repeated attempts at communication;
- ~17% have resolved the issue at the time of publishing;
- 30+ vulnerable hosts were running Travis CI Enterprise, which was built using the vulnerable version of Slanger;
- 1 organization accounted for more than 100 of the vulnerable hosts;
- 2 contacted organizations had a Vulnerability Disclosure Program (VDP) through which I could report the issue;
- 1 contacted organization awarded a bounty as part of their VDP;
- 1 organization sent swag outside of a VDP;
Final thoughts & lessons learned
Before wrapping up, this journey has taught me a number of things I’d like to share.
Blue team:
- As an organization, do not use unsupported or end-of-life software in your production environment without additional security controls. I will forever be able to use this as an anecdote of “the cost of free software.”
- As a software vendor, same remark. By embedding this component in their products, I identified at least two software vendors that unknowingly jeopardized the infrastructure of their clients;
- Additional security controls that might/could have mitigated this issue would be:
- Running the third party component in a sandbox-like environment;
- Have your product security tested. It took a couple of hours only for me to go from discovery to exploitation, so this bug was not so esoteric that it could never be found in a pentest;
- Sharing back with the community. It is likely that the vulnerable component was already found inappropriate for use in production by other software vendors. By looping information like that back, we create a safer web;
- Invest in monitoring. In highly critical environments, the error messages generated by Slanger should trigger at least a few alarm bells, and might help in investigating a potential compromise.
- Make responsible disclosure easy. 43% (!) of the identified vulnerable assets’ owners remain uncontacted, because I was unable to find contact information. When a vulnerability is discovered, a security researcher may try to get in contact with you. Make their life easy and ensure you have some basic guidelines published on your website. For example, this template or the excellent work by
disclose.io might be a good start.
Red team:
- Responsible disclosure is not a straight-forward process — it takes time and dedication even to do it only half-right. Depending on the circumstances, there are probably different approaches you may want to take. I considered the following factors to decide on the approach I took:
- Severity of the bug;
- Livelihood of the vulnerable software’s community;
- Number of affected parties;
- WebSockets appear to be a somewhat less investigated domain worth looking into. Apart from implementation bugs like the one described in this post, I have heard of interesting design bugs that lead to sensitive information being broadcast to all subscribers of a channel;
Timeline
- 11/Feb/2019 – Discovered vulnerability in a bug bounty program;
- 14/Feb/2019 – Discussed the issue with open source author; decided on next steps to mitigate the critical vulnerability;
- 18/Feb/2019 – Discovered the vulnerability in over 160 hosts, including commercial software resulting in their clients’ installs being vulnerable too;
- 27/Feb/2019 – Fixed and merged security bug in GitHub master branch and new Gem version 0.6.1;
- 28/Feb/2019 – Started reaching out to other/smaller affected parties about their vulnerable systems and how to mitigate;
- 4/Mar/2019 – Reached out to 127 asset owners;
- 5/Mar/2019 – 3% of asset owners have fixed the vulnerability;
- 6/Mar/2019 – Travis CI patched the vulnerability in Enterprise version 2.2.7;
- 18/Mar/2019 – Published blog post.
A lot of coffee went into the writing of this article. If it helped you stay secure, please consider buying me a coffee, or invite me to your bug bounty program. 🙂
Nice finding, congrats! Btw.: Is this gnome or xfce running in the screencast you added?
Greetings
I’m not sure, to be honest. It’s the default that comes with https://elementary.io/